

Soloists to Ensembles: the evolving debate between single-agent and multi-agent systems
and why it's going to be an AND versus an OR down the line
When I first began working in tech, data science meant wrestling with tools like R and SAS on single-core machines. Scale quickly became an insurmountable obstacle - simple regression models were manageable, but any meaningful analysis on large datasets turned overnight jobs into multi-day marathons. Then came Hadoop and distributed computing, fundamentally altering our relationship with data. Suddenly, problems once deemed impossible became routine, reshaping entire industries.
Spend enough decades wrangling software at scale, and an inevitable arc emerges - single-threaded CPUs gradually evolved into multi-core architectures. Monolithic databases became harder to manage as systems grew, leading to the rise of microservices and data meshes. Centralized data warehouses eventually gave way to distributed lakes.
Today, large language models are facing a similar transition. We have increased token limits, adopted retrieval augmentation, and improved compression, and still, practical limits remain - relying on a single model is unlikely to be the final stage of artificial intelligence. This growing awareness has sparked intense discussion across the field about whether to keep refining single agents with enriched context, or move toward ensembles of specialized agents. What we seen over the years is that in artificial intelligence, as in civilization, the true leap forward arrives not when one mind grows larger, but when many minds learn to synchronize their strengths and doubts.
the limits of single-agent reasoning
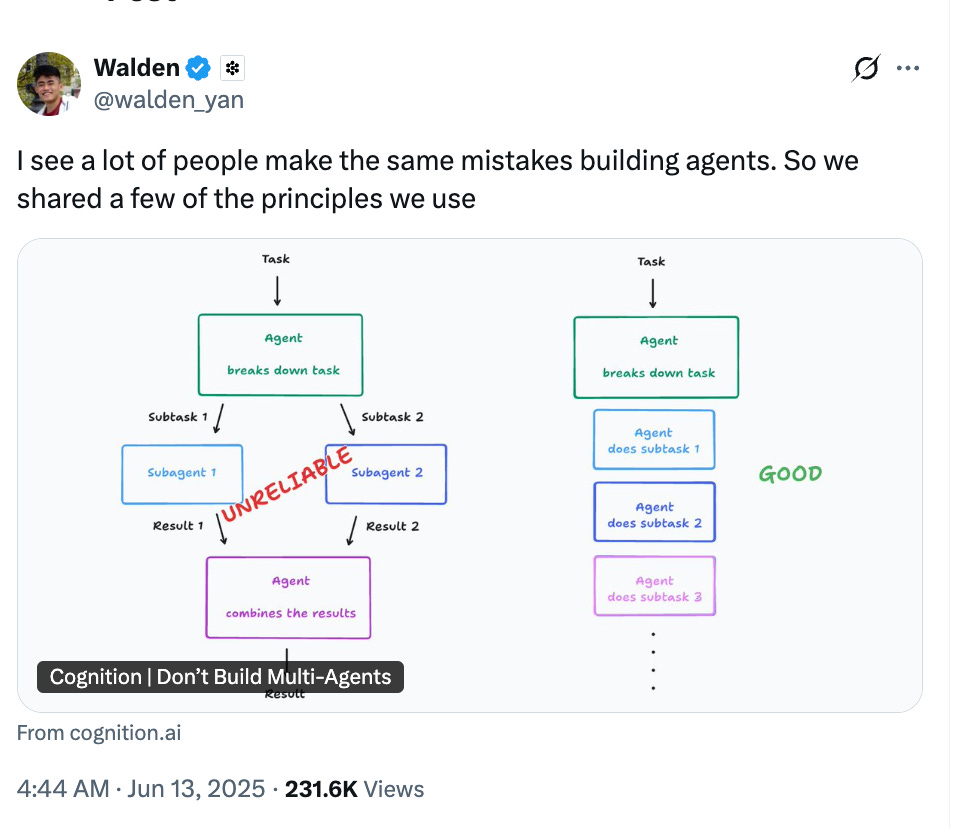
The debate crystallised dramatically on X, albeit for less than 72 hours, when two industry titans took opposing stances two weeks ago. Walden Yan at Cognition AI published “Don’t Build Multi-Agents,” arguing that multi-agent architectures create fragile systems due to poor context sharing and conflicting decisions. Days later, Anthropic countered by releasing their multi-agent research feature, claiming their system outperformed single agents by over 90% on complex tasks (if you find time, i like this recap of the Anthropic paper by Simon Willison). This was not mere academic posturing, but rather represented a fundamental philosophical divide about AI’s architectural future.
Consider the elegant simplicity of a single LLM: It is a bit like a genius researcher moving through a vast library, checking one book at a time. This sequential process means that as new information arrives, older details get pushed aside. You can expand the context and memory of the researcher to capture it all, but research is starting to measure this limit more precisely. Cognitive scientists have found a clear parallel between LLMs and human working memory. Just as a person can only keep track of a few ideas at once, an LLM has a bounded capacity. When that capacity is exceeded, performance reliably drops.
Several recent studies grounded in cognitive load theory confirm that LLMs exhibit human-like failure modes under overload. When tasked with integrating too many facts, a lone model loses the plot: it forgets earlier instructions, fixates on recent details, or averages everything into lukewarm responses. Anthropic’s BrowseComp benchmark illustrated this limitation vividly. When asked to enumerate the entire board roster of the S&P 500’s tech sector, a single Claude Opus trudged along linearly and stalled out before even reaching companies starting with “C.” It wasn’t hardware memory that failed. It was the model’s cognitive maneuvering room.
Similarly, LangChain’s Tau benchmark showed that beyond seven concurrent tool usages, single-agent accuracy nosedived as context became bloated and focus fragmented. Without getting too much into the technicalities, a lone model reasoning through problems resembles someone walking a tightrope - one step at a time, no/low branching, no revisiting paths without starting over. If crucial insights lie down unexplored avenues, the single LLM will miss them entirely. This tunnel vision means models often zero in on particular interpretations and persevere with them even when suboptimal.
two approaches to scaling intelligence
When Yan unintentionally (or, perhaps deliberately) exaggerated the concept of “context engineering,” he signaled a shift beyond prompt engineering toward complete context sharing and unified decision-making. Cognition’s approach follows two core principles - (a) share context across all system components and (b) avoid conflicting decisions by ensuring every action is informed by the full record of prior actions. Their single-agent approach for Devin prioritized reliability and context continuity, embodying the KISS principle. For deep, narrow tasks like programming where memory consistency and logical coherence are paramount, this architecture shows clear advantages. A coding agent needs to remember variable names from hundreds of lines earlier, maintain architectural decisions across multiple files, and ensure that each change does not break prior functionality.
Anthropic took the opposite stance. Their orchestrator-worker model employs Claude Opus as conductor, dissecting high-level goals and delegating subtasks to specialized Claude Sonnets, each with its own token budget and domain focus. Rather than straining one model with millions of tokens, the system distributes work across many agents operating in parallel. Every additional agent in a system is not merely another processor, but a new perspective, reminding us that diversity of thought is as vital to machines as it is to human progress.
The performance gains were striking. In Anthropic’s evaluation, their multi-agent system achieved over 90% higher success on the most difficult research tasks than a single Opus. They did this by rethinking work organization rather than merely scaling parameters.
The Cognition-Anthropic debate revealed an important nuance: architecture choice depends fundamentally on the nature of the task. Multi-agent systems excel in wide and shallow scenarios, such as market research, data gathering, or comparative analysis, where subtasks proceed independently and results are merged later. These breadth-first exploration problems benefit enormously from parallel processing and varied viewpoints.
Conversely, single-agent architectures retain an edge in deep and narrow domains, like programming, legal analysis, or long-form creative writing, where sustained memory and logical consistency matter more than sheer throughput. When Facebook’s legal team analyzed merger contracts, they found that a single specialized model better maintained understanding of contractual relationships than a multi-agent system, which fragmented the analysis.
the economics of running many minds
And we are at a point where delving into this discussion and seeing benefits from multi-agent setups is not just academic theorizing. DHL uses a multi-agent approach to optimize logistics (separate agents for monitoring weather forecasts, port congestion, inventory buffers etc.). Deutsche Telekom processes millions of daily support interactions through a sophisticated multi-agent pipeline (orchestrator agent triaging queries and delegating to specialist agents: billing agents, networking agents, guidance agents etc.). Their VP summed it up simply: this is distributed computing with LLMs on the edges. Bank of America’s Erica operates similarly - agents for fraud patterns, policy information retrieval, and conversation management. The result in all the instances is faster, more accurate responses.
For months, critics have argued that multi-agent systems are too expensive. Anthropic reported their multi-agent system consumed 15 times more tokens than standard chats, a serious cost multiplier. Running one gpt-4 was expensive enough; running five simultaneously looked untenable. But this is changing fast. Model efficiency improves exponentially, not incrementally. gpt-4.1 models, for example, deliver higher output quality at a fraction of the prior cost. OpenAI’s gpt-4.1 mini matches older gpt-4 performance while costing 83% less. Meta’s Llama 4 can run at a fraction of the price on affordable infrastructure. Groq’s Llama-based systems cost just $0.05 per million input tokens. You could feed 20 million tokens for a single dollar, and i have a feeling that by the time I hit send on this essay, prices would drop even further.
Selective participation mechanisms also cut costs by activating only the agents necessary for a given task. When smart orchestration prevents redundant agents from spinning up, the economics improve even further. As the cost of cognition approaches zero, the frontier of AI will be defined less by raw power and more by the elegance with which we orchestrate memory, context, and collective reasoning.
the road ahead for distributed intelligence
Multi-agent architectures bring real challenges though - Cognition AI’s criticism about fragmented contexts and conflicting decisions was not unfounded. Without disciplined orchestration, shared scratchpads, and clear state management, multi-agent systems can collapse into chaos. Anthropic found this the hard way. Early prototypes created dozens of subagents even for simple queries and had agents distracting each other with redundant work. They solved this by enforcing strict boundaries: the lead agent sets goals, assigns tasks, and defines limits for each worker.
Shared memory channels have become essential. Without them, the orchestrator bottlenecks every merge. Most successful systems now rely on common scratchpads where agents contribute interim findings, reading each other’s work like researchers sharing notes. I don’t intend to make it dramatically poetici, but the architecture of intelligence is no longer a contest between giants , and rather is a choreography of specialists, each agent a thread woven together into a tapestry of insight.
Looking ahead, two trends are converging to redefine AI architecture
Economic barriers are collapsing as token costs drop. When running ten agents costs the same as one, the focus will shift fully to effectiveness.
Simultaneously, context engineering and orchestration will become the core skillset. Just as protocol design transformed the chaos of early networking into the internet’s seamless flow, context engineering is poised to become the lingua franca of AI collaboration.
This convergence means multi-agent architectures will move from experimental to default. The question will not be whether we can afford multi-agent systems but whether we can afford not to use them.
Every computational revolution faces the same crossroads: single-unit complexity versus distributed intelligence. History favors distributed systems refined through careful orchestration. Multi-agent systems are not complexity for its own sake-they acknowledge a simple truth: distributed intelligence scales where soloists stall out.
If you’ve read Collapse by Jared diamond, or the Selfish gene by Richard Dawkins, you’d see a common theme that our civilisation thrived not because individual minds grew larger, but because they learned to collaborate. The dawn of multi-agent intelligence reflects our oldest cognitive strategy: many minds working as one. When coordination becomes seamless and economics irrelevant, which it definitely will in a few months, collaboration will triumph. The lone genius has had its run, but i feel fairly certain that the future belongs to the organized collective, architected with the precision of distributed systems and the humility to recognize that no single agent holds all the answers.