
"Hey" Goodhart, what's your LTV/CAC?
"Hey" Goodhart, what's your LTV/CAC?
Match cutting, LLMs, Slack summaries, Goodhart in ML, Tomasz Tunguz & Unstable Diffusion
November was a relatively calm month at work, so I decided to run some lifestyle experiments - waking up at 5:30 a.m., running 5 miles before 7, cold shower, no coffee in the first 2 hours, closing work at 6 p.m. every day and reading for 90 minutes, spending less than 60 minutes each week on social media,and a few other small, fringe changes. Basically, all the usual stuff people write on Twitter, but I never bothered to adopt. I have tons of bookmarks and screenshots to return to every day (more on that in the next email); here are some of the interesting articles from the past 2 weeks.
Match cutting at scale [link]: I am a huge admirer of well-executed match cutting (Citizen Kane, Lawrence of Arabia, Stanley Kubrick's 2001: A Space Odyssey, Alfred Hitchcock's Psycho…). A match cut is a transition between two images in film that uses comparable visual framing, composition, or movement to move the audience from one scene to the next. It is a powerful visual storytelling tool that is used to connect two scenes.

This is an excellent read in which the Netflix team discusses some of their work on match cuts. One of the most intriguing articles I've read this month.
Diagnostic Value of LTV/CAC [link]: Using composite metrics as sole indicators of business health is one of the industry concepts I have always been skeptical about throughout my professional career. LTV/CAC is a notable example - I've seen numerous organizations host a trending view of the measure, examine the patterns over time, establish benchmarks versus competitors, and blame/praise the incorrect levers for the trend. Organizations rarely investigate how to maximize the diagnostic utility of LTV/CAC. Here's a quick read from Tomasz Tunguz on exploiting functional forms of LTV/CAC to do quick business experiments. Also, if you are a part of a young startup, Tomasz also explains how Payback period could be a superior health statistic than iterating through misleading LTV extrapolation.
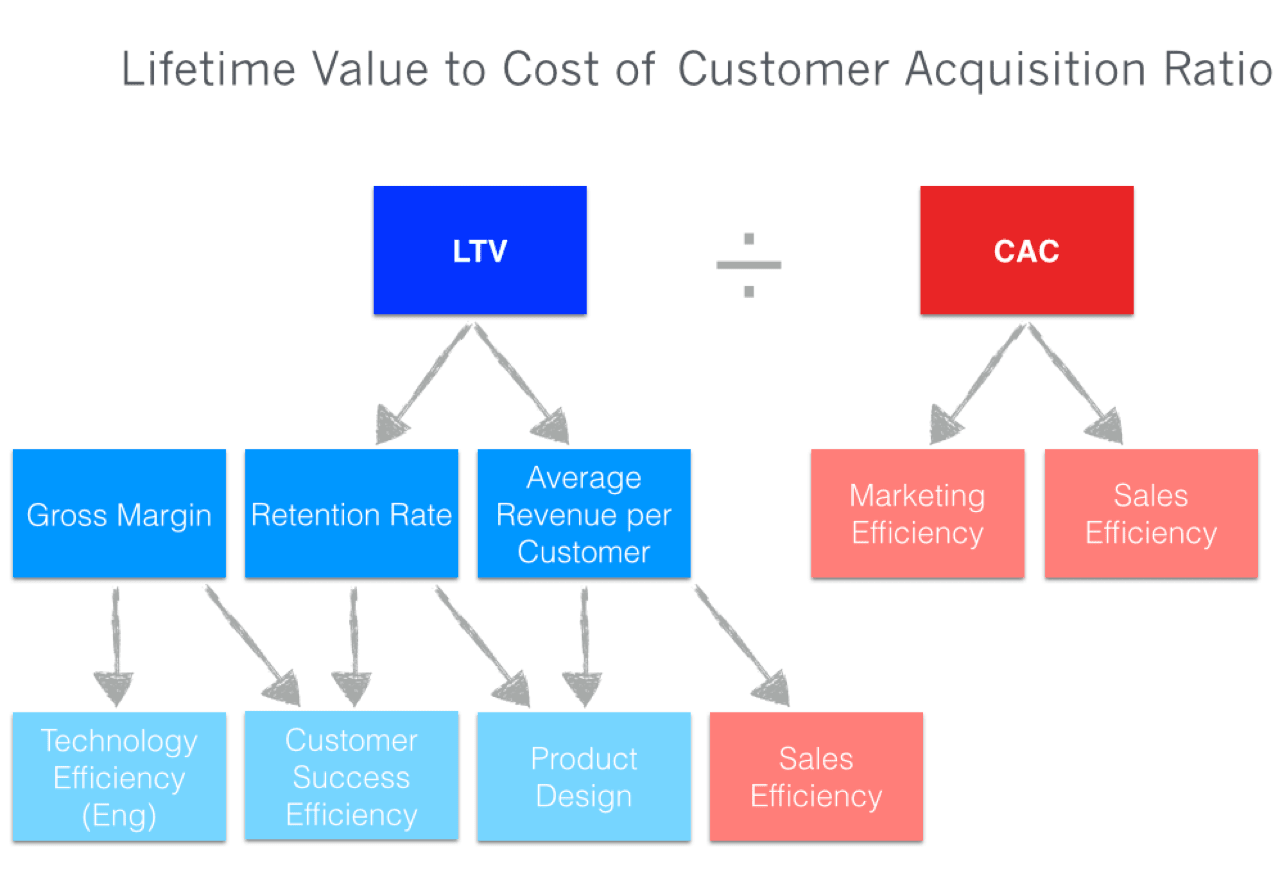
PS: Btw, here’s something that’s keeping me busy at work in November.
Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI [link]: As machine learning (ML) research progresses toward large-scale models capable of performing a wide range of downstream tasks, a shared understanding of a dataset's origin, development, intent, and evolution becomes increasingly vital for the responsible and informed construction of ML models. However, dataset expertise, including use and implementation, is frequently dispersed across teams, individuals, and even time.
Earlier this year at the ACM Conference on Fairness, Accountability, and Transparency (ACM FAccT), Google published Data Cards, a dataset documentation framework aimed at increasing transparency across dataset lifecycles. Data Cards are transparency artifacts that provide structured summaries of ML datasets with explanations of processes and rationale that shape the data and describe how the data may be used to train or evaluate models. At minimum, Data Cards include the following: (1) upstream sources, (2) data collection and annotation methods, (3) training and evaluation methods, (4) intended use, and (5) decisions affecting model performance. Here’s the full PDF. Started using the cards at work myself - common sense, mostly - but great resource when scaled across the org.
No more “Hey” in Siri [link]: According to reports, Apple intends to reduce the "Hey Siri" trigger phrase to just "Siri." Switching to a single trigger word will allow Apple to compete with Amazon's Alexa, which can currently respond to commands with "Alexa" rather than "Hey Alexa." Before shutting down Cortana, Microsoft changed its wake phrase from "Hey Cortana" to just "Cortana" (don't make any incorrect bayesian assumptions here). The change would also put Apple one step ahead of Google, which still requires users to say "Hey Google" or "OK Google" before using its services.
Too much efficiency makes everything worse [link]: Goodhart's law states that, when a measure becomes a target, it ceases to be a good measure. Goodhart proposed this in the context of monetary policy, but it applies far more broadly. In the context of overfitting in machine learning, it describes how the proxy objective we optimize ceases to be a good measure of the objective we care about.
The future of AI stack [link]: In 2022, generative AI (artificial intelligence) has been the subject of much anticipation and hype. Images generated by generative machine learning models like DALL-E and Stable Diffusion are all over social media sites like Twitter and Reddit. Despite the market slump, startups building solutions on top of generative models are receiving funding. Furthermore, many tech firms are incorporating generative models into their standard offerings. John McDonnell discusses the evolution of the AI stack and offers his thoughts on why the future of the technology will be "Action-Driven" in this essay.
Move faster, wait less: Improving code review time at Meta [link]: Meta examined several metrics to understand more about code review bottlenecks that result in dissatisfied engineers, and used that knowledge to construct features that assist speed up the code review process without losing review quality. They discovered a link between long diff review times (P75) and engineer discontent. Their methods for surfacing diffs to the appropriate reviewers at critical points in the code review lifecycle have greatly improved the diff review experience.
Overwhelmed with the volume of Slack channels and threads? [link]: TheGist (website here), a startup worth keeping an eye on (and testing out on your company slack if the admin permits), leverages the magic of AI to go over the conversation, and instantly creates a short summary for you. The backstory is pretty fascinating too - Itay Dressler and Itzik Ben Bassat, who’ve held various software engineering and executive roles at startups together over the years, are accustomed to exchanging brief messages. Ben Bassat has ADHD, and for that reason prefers to keep texts on the shorter side. But as he and Dressler were faced with wrangling an increasing number of tools at their employers, they came to realize they weren’t the only ones who could benefit from more succinct updates. So they founded TheGist with the grand mission of “simplifying information consumption in workplace communications and data” through instant highlights.
If you are interested in summaries and detest information overload, there’s another great release from the last week. Google is bringing its expertise in communications apps to remedy all conversational crisis in your Workspace Spaces Chats. Starting soon, the messages in your conversations will be summarized right in your Chats, inside Spaces in Workspaces! Selected Premium Workspaces, anyway.
Very large language models and how to evaluate them [link]: Zero-shot evaluation is a popular way for researchers to measure the performance of large language models, as they have been shown to learn capabilities during training without explicitly being shown labeled examples. The Inverse Scaling Prize is an example of a recent community effort to conduct large-scale zero-shot evaluation across model sizes and families to discover tasks on which larger models may perform worse than their smaller counterparts.
PS - I am a big fan of huggingface and the work they’re doing in the community. If you’re interested to learn more about the evaluation hub, here’s a practical explainer.
The Illustrated Stable Diffusion [link], and the debates on Ethics and Social risks around Unstable diffusion [link]: Creating beautiful graphics from word descriptions is remarkable and signals a shift in how humans produce art. Stable Diffusion is a milestone because it made a high-performance model available to the public (picture quality, speed, and minimal resource/memory requirements). You may question how AI image generating works after using it. Here's a great visual primer on how Stable Diffusion works.
Following the release of Stable Diffusion earlier this year, groups on Reddit and 4chan used the AI system to generate realistic and anime-style images of nude characters as well as non-consensual false nude imagery of celebrities. While Reddit soon shut down many of the subreddits dedicated to AI porn, and communities like NewGrounds, which allows some forms of adult art, outright prohibited AI-generated artwork, new forums sprung up to fill the void. Unstable Diffusion, by far the largest, is creating a business around AI algorithms designed to make high-quality porn. The server’s Patreon started to keep the server running as well as fund general development is currently raking in over $2,500 a month from several hundred donors. Full article on Unstable diffusion originally covered in techcrunch here.
Other stuff worth a shout-
Why don't American traffic signs use pictograms as much as other countries?
Meet the AI helping you choose what to watch next.
Burn multiple: How to reinvent your product growth strategy for the tech downturn
Will low and no code tools ever truly disrupt tech development?
The Most Comprehensive List of Kaggle Solutions and Ideas
My professor says I would not graduate my PhD, although I fulfilled all the requirements
Burnout is very real, and here’s a wonderful keynote addressing that elephant in the room