grunt data | ethics when it doesn't make sense | tales of scaling
Creating this newsletter takes hours of effort each week. Forwarding this to someone who’d find it useful - 30 seconds.
Support this project! ❤️ Share this with 3 friends.
🚀 Got this forwarded from a friend? Sign up here
Despite all the energy and momentum in the tech startup segments, there is still a tremendous amount of confusion around what technologies are on the leading end of this trend and how they are used in practice. In the last two years, folks at a16z talked to hundreds of founders, corporate data leaders, and other experts – including interviewing 20+ practitioners on their current data stacks – in an attempt to codify emerging best practices and draw up a common vocabulary around data infrastructure. This post begins to share the results of that work and showcase technologists pushing the industry forward.
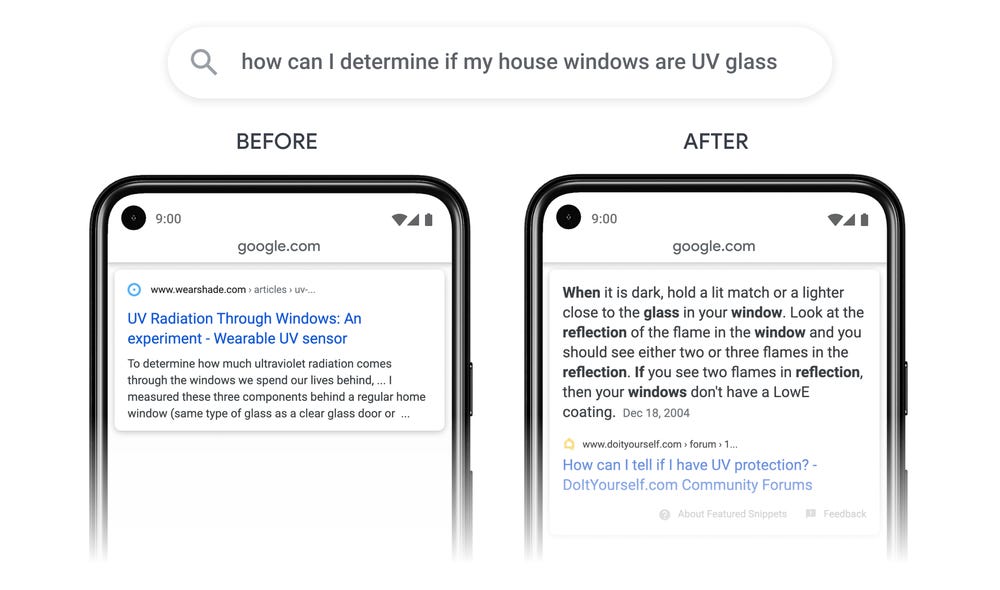
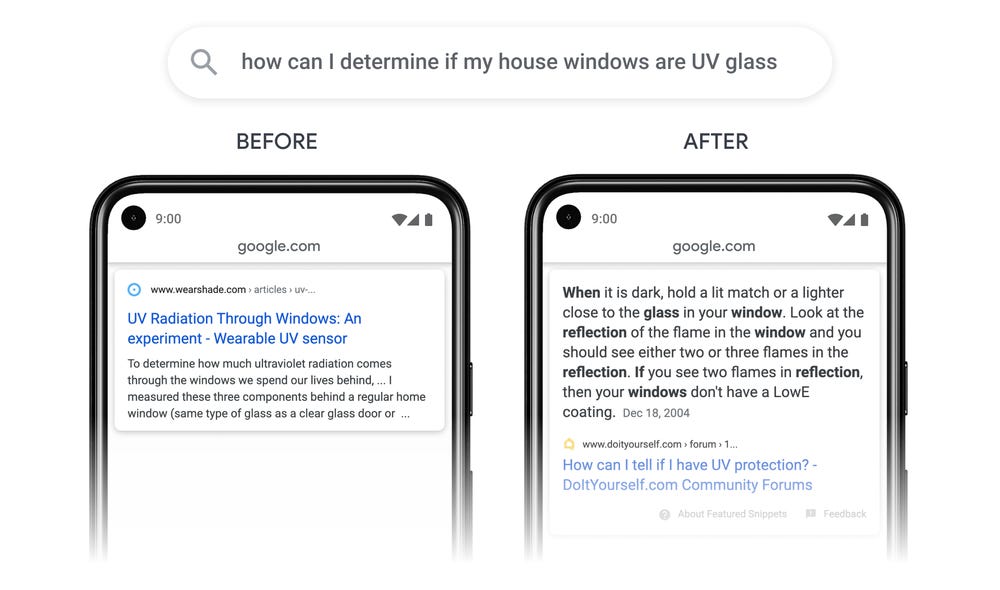
During its Search On livestream, Google shared how they're bringing the most advanced AI into their products to further their mission to organize the world’s information and make it universally accessible and useful. Read more here
Putting the engineer back in machine learning engineer : notes around starting the machine learning journey
Poor diversity and other reasons that make data messy and end up affecting model training
A major limitation in Reinforcement learning is that current methods require vast amounts of training experience. For example, in order to learn how to play a single Atari game, an RL agent typically consumes an amount of data corresponding to several weeks of uninterrupted playing.
One possible reason for this discrepancy is that, unlike humans, RL agents usually learn a new task from scratch. We would like our agents to leverage knowledge acquired in previous tasks to learn a new task more quickly, in the same way that a cook will have an easier time learning a new recipe than someone who has never prepared a dish before.
Here’s a glimpse into how to endow RL agents with this abilityThere’s hardly a complete index to every module, function and class in the Python standard library all in one easy-to-browse place. Here’s one good attempt at it
Always wanted someone to review and simplify machine learning and AI papers on arxiv but couldn’t find help? Here are some references: Review of machine learning/AI papers
It’s growing further: The 2020 Data & AI Landscape

How disturbing would it be if you were an evil data scientist?
This is an old reference but a very beautiful piece from Wes’ blogs. For people who transitioned from strict pandas to apache arrow, this would warm up the nostalgia
Ok, time for some fun pause here - speaker-aware talking head animation
 AK@ak92501MakeItTalk: Speaker-Aware Talking Head Animation code released project page: people.umass.edu/~yangzhou/Make… github: github.com/yzhou359/MakeI…11:40 PM · Oct 14, 202027 Reposts · 104 Likes
AK@ak92501MakeItTalk: Speaker-Aware Talking Head Animation code released project page: people.umass.edu/~yangzhou/Make… github: github.com/yzhou359/MakeI…11:40 PM · Oct 14, 202027 Reposts · 104 Likes
For the more serious folks, details hereWhen the world moved to “big data” majority of companies were (and, stil l are) struggling with small data. Two techniques in particular — transfer learning and collective learning — have proven critical in transforming small data into big data, allowing average-sized companies to benefit from ML use cases that were once reserved only for Big Tech. And because just 15% of companies have deployed AI or ML already, there is a massive opportunity for these techniques to transform the business.
Thoughts here.Differential privacy is a mathematically rigorous framework for quantifying the anonymization of sensitive data. It’s often used in analytics, with growing interest in the machine learning community. With the release of Opacus, Facebook hopes to provide an easier path for researchers and engineers to adopt differential privacy in ML, as well as to accelerate DP research in the field
In this podcast episode from thedataexchange, Max Pumperla (maintainer of Hyperopt) provides an update and a technical description of how Pathmind uses reinforcement learning, RLLib, and Tune, to help users of AnyLogic, a widely used software for simulations in business applications
Listen hereWhen do you call a platform a machine learning platform?


Scaling AI for distributed Big Data is a key challenge that arises as AI moves from experimentation to production. In addition to scaling, another key challenge in practice is how to seamlessly integrate data processing and AI programs into a single unified pipeline. Conventional approaches would set up two separate clusters, one for big data processing, and the other dedicated to deep learning and AI. But this not only introduces a lot of data transfer overhead, but also requires additional efforts for managing separate workflows and systems in production. In this post, Jason Dai (SPE and CTO at Intel) shares his efforts in building the end-to-end big data and AI pipelines using Ray and Apache Spark
Hands down the best formal notes around on Practical Data Ethics. Also, bonus read here
Source code for The Economist’s model for predicting State and national presidential election forecasts. Leverages a dynamic multilevel Bayesian model built using R (ummm..) and Stan.
Improving on Pierre Kremp’s implementation of Drew Linzer’s dynamic linear model for election forecasting (Linzer 2013), the model (1) add corrections for partisan non-response, survey mode and survey population; (2) uses informative state-level priors that update throughout the election year; and (3) specifies empirical state-level correlations from political and demographic variables.https://github.com/TheEconomist/us-potus-model
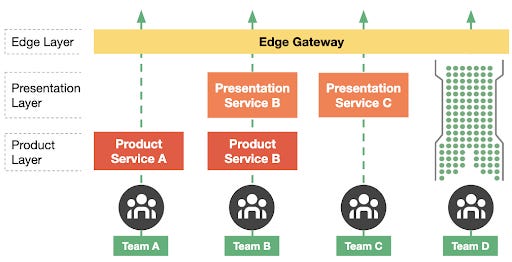
Notes on different phases of the evolution of Uber’s API gateway that powers Uber products. Walks through the framework’s history to understand the evolution of architectural patterns that occurred alongside this breakneck growth phase. Also speaks of this evolution over three generations of the gateway systems, exploring their challenges and their responsibilities
How does one benchmark AI? Novel and fantastic build by the folks at Facebook
Organizing the world into abstract categories does not come easily to computers, but in recent years researchers have inched closer by training machine learning models on words and images infused with structural information about the world, and how objects, animals, and actions relate. In a new study at the European Conference on Computer Vision this month, researchers unveiled a hybrid language-vision model that can compare and contrast a set of dynamic events captured on video to tease out the high-level concepts connecting them.