managing scale, being model driven, metrics that matter & setting benchmarks
❤️ Want to support this project? Forward this email to three friends!
🚀 Got this forwarded from a friend? Sign up here
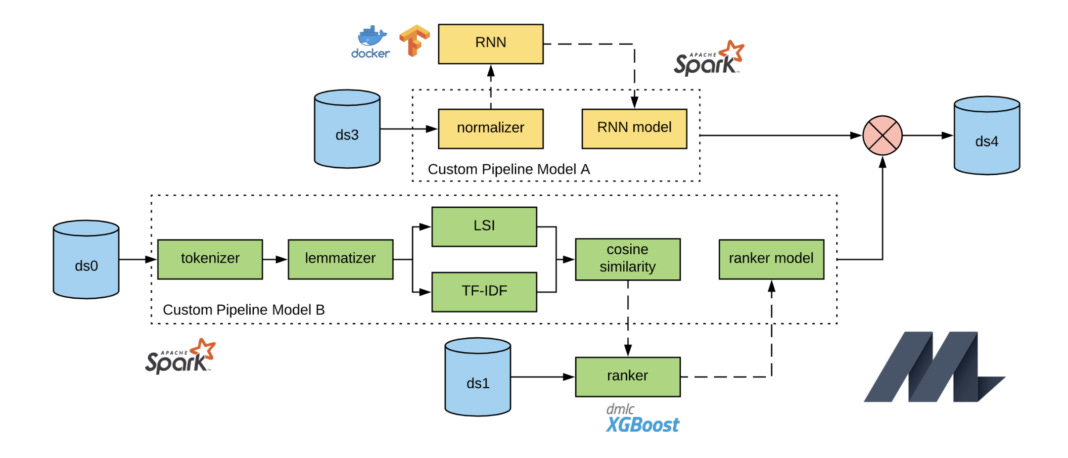
Evolving Michelangelo Model Representation for Flexibility at Scale
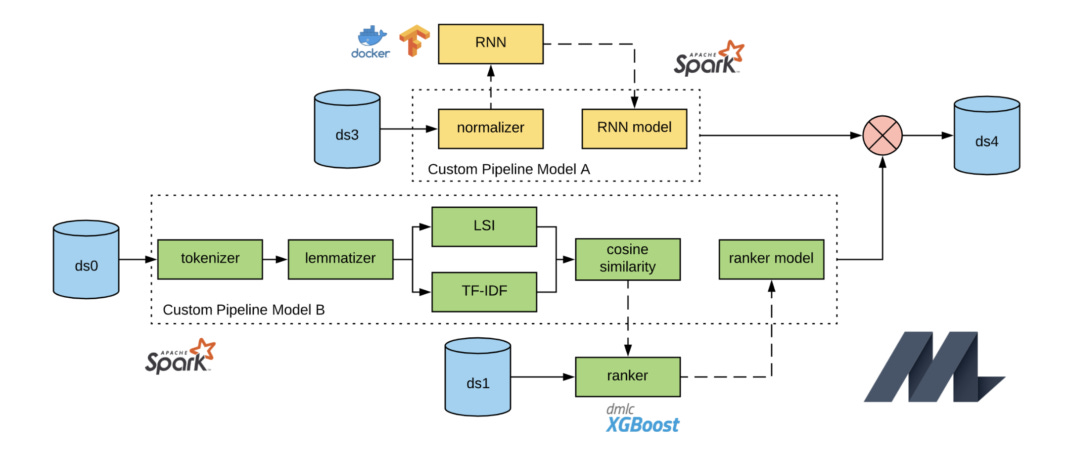
Most Michelangelo models (more here) are based on Apache Spark MLlib, a scalable machine learning library for Apache Spark. To handle high-QPS online serving, Michelangelo originally supported only a subset of Spark MLlib models with in-house custom model serialization and representation, which prevented customers from flexibly experimenting with arbitrarily complex model pipelines and inhibited Michelangelo’s extensibility velocity. To address these issues, the team at Uber evolved Michelangelo’s use of Spark MLlib, particularly in the areas of model representation, persistence, and online serving.
Turn Python Scripts into Beautiful ML Tools
Streamlit, an app framework built for ML engineers
Billion-scale semi-supervised learning for state-of-the-art image and video classification
Facebook’s new approach, which they call semi-weak supervision, is a new way to combine the merits of two different training methods: semi-supervised learning and weakly supervised learning. It opens the door to creating more accurate, efficient production classification models by using a teacher-student model training paradigm and billion-scale weakly supervised data sets. If the weakly supervised data sets (such as the hashtags associated with publicly available photos) are not available for the target classification task, the proposed method can also make use of unlabeled data sets to produce highly accurate semi-supervised models.
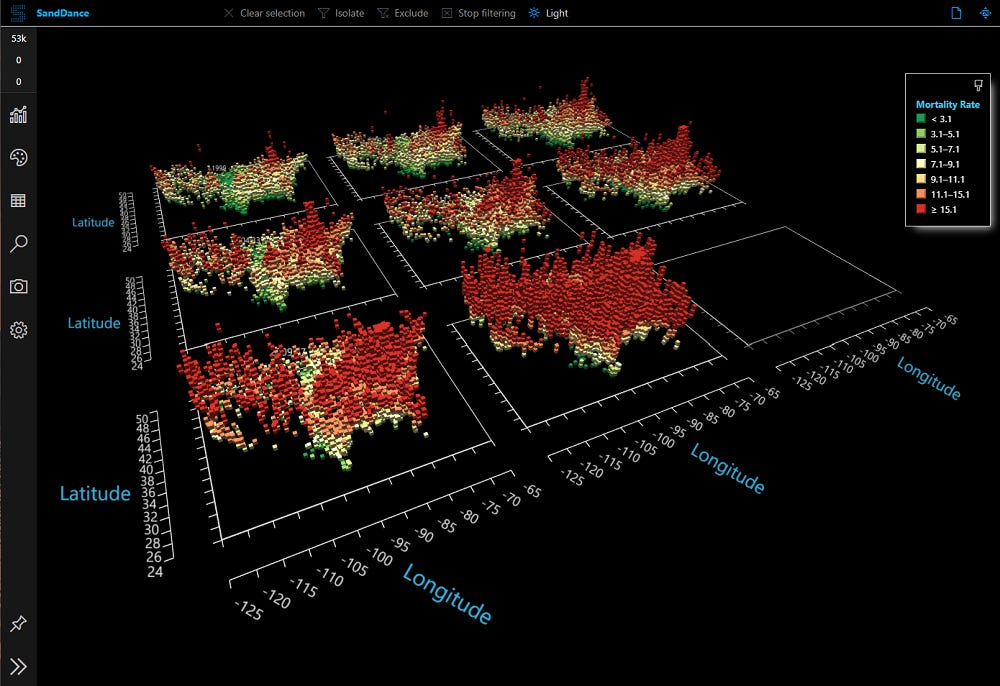
Microsoft open sources SandDance, a visual data exploration tool
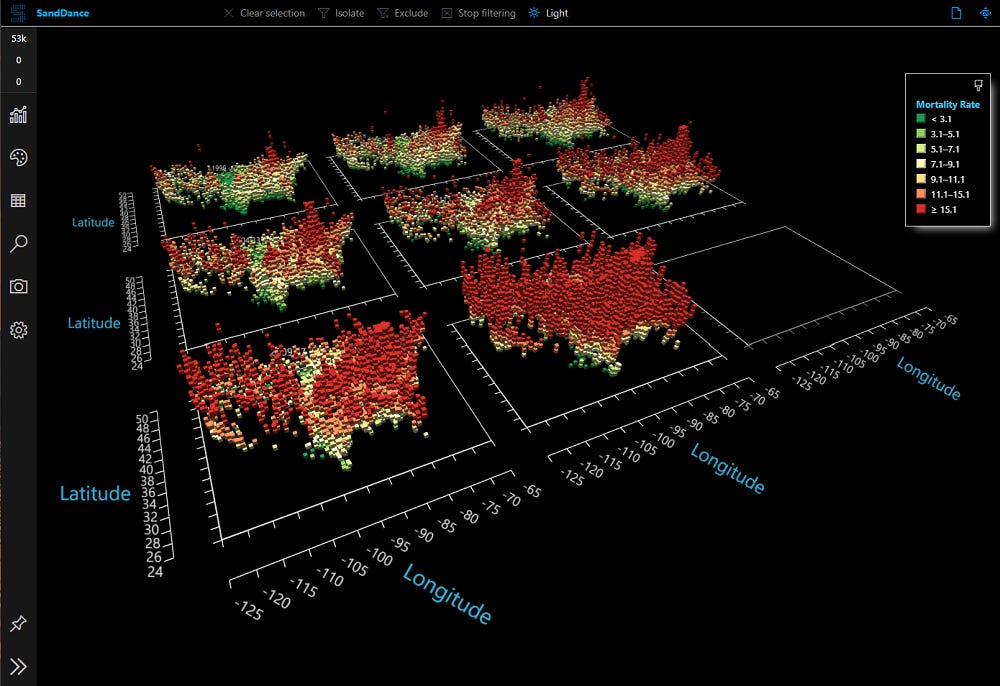
SandDance, the beloved data visualization tool from Microsoft Research, has been re-released as an open source project on GitHub. This new version of SandDance has been re-written from the ground up as an embeddable component that works with modern JavaScript toolchains. The release is comprised of several components that work in native JavaScript or React apps, in addition to using various open source libraries. We hope that with this new architecture, SandDance will be vastly more extensible, enabling new chart types, layers, and interactions, as well as being incorporated into new, vertical applications.
On Being Model-driven: Metrics and Monitoring
This article covers a couple of key Machine Learning (ML) vital signs to consider when tracking ML models in production to ensure model reliability, consistency and performance in the future.
Recent advances in low-resource machine translation
In the pursuit of building more powerful, flexible Machine Translation systems, Facebook AI has recently achieved two major milestones for low-resource languages.
A novel approach that combines several methods, including iterative back-translation and self-training with noisy channel decoding, to build the best-performing English-Burmese MT system at the Workshop on Asian Translation (WAT) competition, with a gain of 8+ BLEU points over the second-best team.
A state-of-the-art approach for better filtering of noisy parallel data from public websites with our LASER (Language-Agnostic SEntence Representations) toolkit. Using this technique, they have taken first place for the shared task on corpus filtering for low-resource languages of Sinhala and Nepali at the Fourth Conference on Machine Translation (known as WMT).
{Podcast} Machine learning and analytics for time series data
Arun Kejariwal and Ira Cohen on building large-scale, real-time solutions for anomaly detection and forecasting. {Arun Kejariwal's and Ira Cohen’s joint session “Sequence to sequence modeling for time series forecasting” is part of a strong slate of sessions on AI for temporal data and time series at the O'Reilly Artificial Intelligence conference in London, 14-17 October 2019.{
Amazon SageMaker Ground Truth now features built-in workflows for label verification, and label adjustment for bounding boxes and semantic segmentation. With these new workflows, you can chain an existing Amazon SageMaker Ground Truth labeling job to a verification or adjustment job, or you can import your existing labels for a verification or adjustment job.
Buffet lines are terrible, but let's try to improve them using computer simulations

Fantastic theoretical notes on simulating different frameworks for tackling long buffet lines (or, any lines/queues)
Quick recap: Kaplan Meier Mistakes
A quick compendium on how to avoid common survival analysis mistakes and improve prognostic factor research
{Video} Best Practices for Operationalizing Data Science & Machine Learning
Roger Magoulas, VP of Radar at O'Reilly Media, Inc., asks: Why is the final mile such a challenge for so many organizations who are working on AI and machine learning? Dataiku Data Scientist Jed Dougherty has answers.
Winner Interview with Shivam Bansal | Data Science for Good Challenge: City of Los Angeles
Summary of the winning work by Shivam Bansal for the latest ‘Data Science for Good’ challenge. Shivam is the Kaggle Kernels Grandmaster with the highest global rank of 2 and is the winner of three Data Science for Good Challenges.
{Video interview} Setting benchmarks in machine learning
Dave Patterson and other industry leaders discuss how MLPerf will define an entire suite of benchmarks to measure performance of software, hardware, and cloud systems.
Unarxiving Arxiv
Mass Personalization of Deep Learning
The paper discusses training techniques, objectives and metrics toward mass personalization of deep learning models.
Demand Forecasting in the Presence of Systematic Events: Cases in Capturing Sales Promotions
In practice, the forecasts generated by baseline statistical models are often judgmentally adjusted by forecasters to incorporate factors and information that are not incorporated in the baseline models. There are however systematic events whose effect can be effectively quantified and modeled to help minimize human intervention in adjusting the baseline forecasts. This paper showcases a novel regime-switching approach to quantify systematic information/events and objectively incorporate them into the baseline statistical model. The simple yet practical and effective model can help limit forecast adjustments to only focus on the impact of less systematic events such as sudden climate change or dynamic market activities.
Master your Metrics with Calibration
Machine learning models deployed in real-world applications are often evaluated with precision-based metrics such as F1-score or AUC-PR (Area Under the Curve of Precision Recall). Heavily dependent on the class prior, such metrics may sometimes lead to wrong conclusions about the performance. For example, when dealing with non-stationary data streams, they do not allow the user to discern the reasons why a model performance varies across different periods. In this paper, the authors propose a way to calibrate the metrics so that they are no longer tied to the class prior.