AI startups, data augmentation, labelling & bugs
++ new stuff from git and arxiv
Hi, there! Apart from the usual notes and essays, we have 2 new sections this week - selected research papers from Arxiv, and some really useful & interesting Git repositories. Last week was busy, and the ML landscape stayed more or less calm, but we got that covered with some very interesting pick of narratives, interviews and lessons.
If you like the content, do share the newsletter with your friends and colleagues!
Notes and essays
OpenAI Wants to Move Slow and Not Break Anything
Last week, OpenAI released its third and second-largest iteration of the algorithm that generates text that is comprehensible to humans. The underlying network has 774M parameters, more than six times as many as the first version the company released. This means that researchers using the algorithm to make generative text suggestion apps, chatbots, or even auto-complete for code now have a better algorithm to work with.
But while working on the technical aspects of making an algorithm that can recreate human writing, OpenAI has also been thinking about how to minimize the danger of releasing powerful A.I. onto the internet. On Tuesday, it announced partnerships with four universities — Cornell University, Middlebury, the University of Oregon, and the University of Texas at Austin — to track how the models can be used for misinformation and terrorism, as well as analyzing the algorithm for bias and testing how to discern human-written text from algorithmically-generated text.
What makes a good conversation
While neural Language Model (LM) based approaches have been successful for tasks such as machine translation and sentence compression, they have well-documented difficulties with tasks such as story generation and dialogue flows - tasks with repetitious and generic output (under certain decoding algorithms, such as beam search.
More broadly, neural LMs seem to struggle to make the high-level decisions that are necessary to sustain a long story or dialogue.
In this article, the folks at Stanford AI lab use chitchat dialogue as a setting to better understand the issues raised above. In particular, they control multiple attributes of generated text and human-evaluate multiple aspects of conversational quality, in order to answer three main research questions:
How effectively can we control the attributes?
How do the controllable attributes affect aspects of conversational quality?
Can we use control to make a better chatbot overall?
Amenity Detection and Beyond — New Frontiers of Computer Vision at Airbnb
The team at Airbnb tested a few different object detection API services with their listing photos. Even though the API services were able to detect certain amenities, the labels predicted were too vague. In a home sharing business like Airbnb, knowing that kitchenware exists in a picture does not tell much other than the room type. Likewise, knowing there is a table in the picture doesn’t help either. The default models won’t know what kind of a table it is, or what it could be used for.
Airbnb’s actual goal was to understand whether the detected amenities provide convenience for guests. Can guests cook in a given home? Do they have specific cookware they want? Do they have a dining table of a decent size to host enough people if it is a family trip? In the above article, the team highlights their amenity detection approach that’s currently being used for their listings.
1000x Faster Data Augmentation
Data augmentation is a strategy that enables practitioners to significantly increase the diversity of data available for training models, without actually collecting new data. Data augmentation techniques such as cropping, padding, and horizontal flipping are commonly used to train large neural networks. However, most approaches used in training neural networks only use basic types of augmentation. While neural network architectures have been investigated in depth across the industry, less focus has been put into discovering strong types of data augmentation and data augmentation policies that capture data invariances.
In this blog post the team at Berkley AI research introduces Population Based Augmentation (PBA), an algorithm that quickly and efficiently learns a state-of-the-art approach to augmenting data for neural network training. PBA matches the previous best result on CIFAR and SVHN but uses one thousand times less compute, enabling researchers and practitioners to effectively learn new augmentation policies using a single workstation GPU.
Interesting narratives & interviews
Why AI Companies Can’t Be Lean Startups - A Conversation with Matt Turck of FirstMark Capital
What does it take to raise seed funding as an AI-first SaaS startup? - The AI-first SaaS Funding Napkin guidance from the team at Point Nine
Lessons I Learned Being a Woman in Technology - Some really fantastic insights and guidelines from Jun Wu
The consequences of deploying automation without considering ethics could be disastrous
AI is being used in a surprising number of applications, making judgments about job performance, hiring, loans, and criminal justice among many others. Most people are not aware of the potential risks in these judgments. They should be. There is a general feeling that technology is inherently neutral — even among many of those developing AI solutions. But AI developers make decisions and choose tradeoffs that affect outcomes. Developers are embedding ethical choices within the technology but without thinking about their decisions in those terms.
In this article, Kyle Dent highlights the consequences of deploying automation without considering ethics.
In today’s day and age, if data is the new oil, labelled data is the new gold. Data Scientists often spend a lot of their time thinking about “Big Data” issues, because these are the easiest to solve with deep learning. However, they often overlook the much more ubiquitous and difficult problems that have little to no data to train with. In this work Microsoft’s ML blog team shows how even without any data, one can create an object detector for almost anything found on the web. This effectively bypasses the costly and resource intensive processes of curating datasets and hiring human labelers, allowing one to jump directly to intelligent models for classification and object detection completely in sillico.
The article illustrates application of this technique to help monitor and protect the endangered population of snow leopards.
Identifying and eliminating bugs in learned predictive models
Bugs and software have gone hand in hand since the beginning of computer programming. Over time, software developers have established a set of best practices for testing and debugging before deployment, but these practices are not suited for modern deep learning systems. Today, the prevailing practice in machine learning is to train a system on a training data set, and then test it on another set. While this reveals the average-case performance of models, it is also crucial to ensure robustness, or acceptably high performance even in the worst case. In this article, the team at DeepMind describes three approaches for rigorously identifying and eliminating bugs in learned predictive models: adversarial testing, robust learning, and formal verification.
A web application to extract key information from journal articles
Academic papers often contain accounts of new breakthroughs and interesting theories related to a variety of fields. However, most of these articles are written using jargon and technical language that can only be understood by readers who are familiar with that particular area of study.
Non-expert readers are thus typically unable to understand scientific articles, unless they are curated and made more accessible by third parties who understand the concepts and ideas contained within them. With this in mind, a team of researchers at the Texas Advanced Computing Center in the University of Texas at Austin (TACC), Oregon State University (OSU) and the American Society of Plant Biologists (ASPB) have set out to develop a tool that can automatically extract important phrases and terminology from research papers in order to provide useful definitions and enhance their readability.
Summarizing popular Text-to-Image Synthesis methods with Python
Automatic synthesis of realistic images from text have become popular with deep convolutional and recurrent neural network architectures to aid in learning discriminative text feature representations. Discriminative power and strong generalization properties of attribute representations even though attractive, its a complex process and requires domain-specific knowledge. In comparison, natural language offers a general and flexible interface for describing objects in any space of visual categories. The best thing is to combine generality of text descriptions with the discriminative power of attributes.
This blog addresses different text to image synthesis algorithms using GAN (Generative Adversarial Network) thats aims to directly map words and characters to image pixels with natural language representation and image synthesis techniques.
a(rX)iv for this week
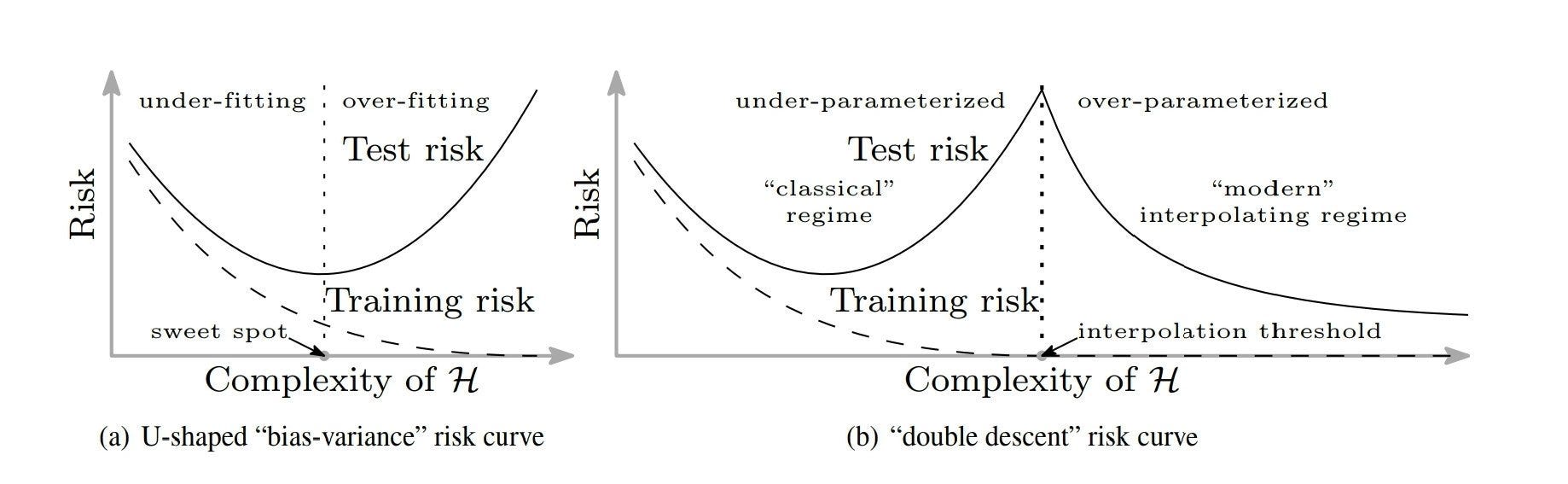
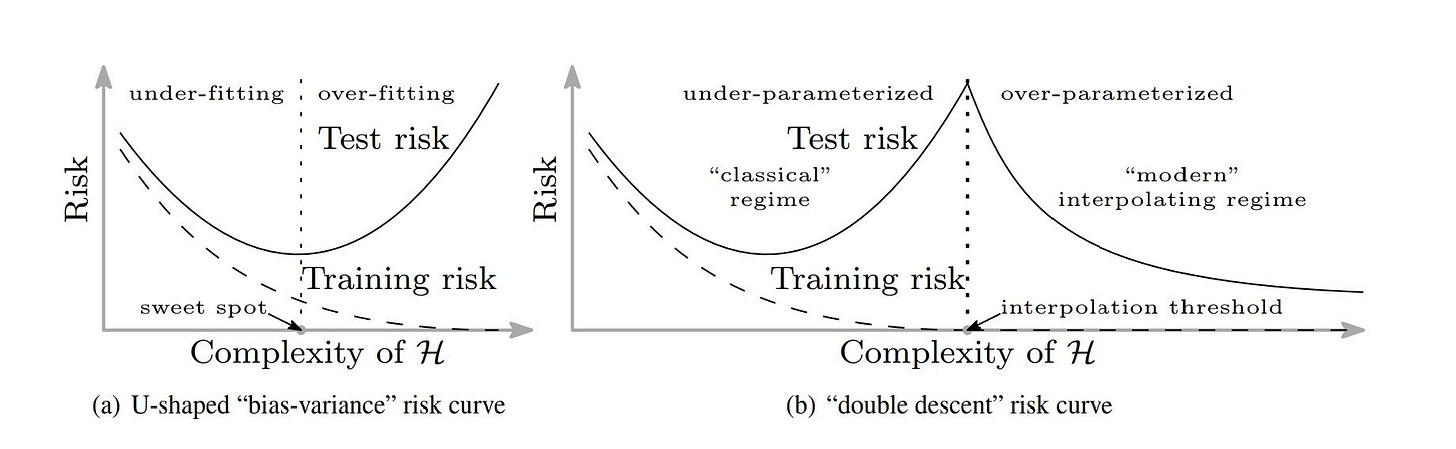
Reconciling modern machine learning and the bias-variance trade-off
Very interesting paper with empirical observations of "double descent"/two-regime behaviour in test performance of complex ML models as a function of (L2 norm-based) model complexity.
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
Deep learning based methods have been widely used in industrial recommendation systems (RSs). Previous works adopt an Embedding & MLP paradigm: raw features are embedded into low-dimensional vectors, which are then fed on to MLP for final recommendations. However, most of these works just concatenate different features, ignoring the sequential nature of users' behaviors. In this paper, the authors propose to use the powerful Transformer model to capture the sequential signals underlying users' behaviour sequences for recommendation in Alibaba
Atlas: A Dataset and Benchmark for E-commerce Clothing Product Categorization
Product categorization is a large scale classification task that assigns a category path to a particular product. Research in this area is restricted by the unavailability of good real-world datasets and the variations in taxonomy due to the absence of a standard across the different e-commerce stores. In this paper, the authors introduce a high-quality product taxonomy dataset focusing on clothing products which contain 186,150 images under clothing category with 3 levels and 52 leaf nodes in the taxonomy. They explain the methodology used to collect and label this dataset. Further, thry also establish the benchmark by comparing image classification and Attention based Sequence models for predicting the category path.
What’s in a (git) repo?